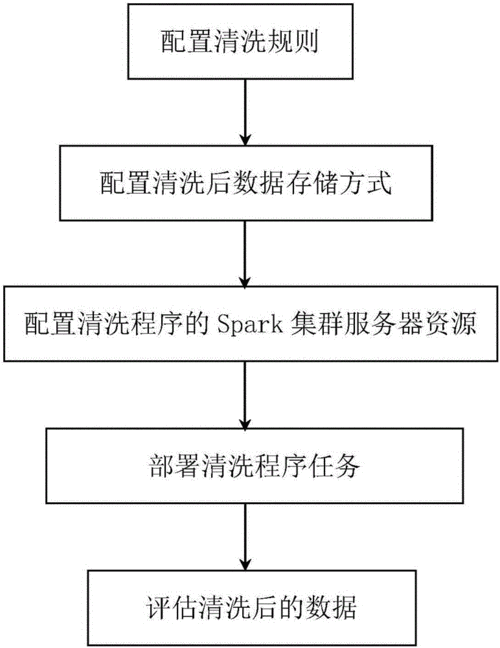
数据清洗工具操作指南
数据清洗是数据分析的重要步骤,它涉及到数据的质量提升和数据的预处理。在这个过程中,我们会使用到一些工具来帮助我们完成数据清洗的任务。以下是根据搜索结果整理出的一些数据清洗工具及其操作指南。
Python数据清洗工具
NumPy和Pandas是Python中最常用的
data
cleaning
工具。NumPy提供了大量的数据清洗功能,如排序、搜索、数据类型的获取和元素的运算等。Pandas则提供了更多的数据结构和方法,如Series、DataFrame以及各种数据筛选、增加、删除、修改和查找的方法。
NumPy:NumPy常用的数据结构包括array,可以使用内置的函数如arange、linspace、zeros等创建。NumPy的sort函数用于进行从小到大的排序,argsort函数返回的是数据中从小到大的索引值。数据的搜索可以使用np.where函数,可以根据条件返回满足条件的情况。
Pandas:Pandas常用的数据结构包括Series和DataFrame,可以通过索引或位置进行数据的筛选和操作。Pandas提供了to_csv方法用于快速保存数据。在数据清洗过程中,Pandas还提供了insert方法用于在数据中添加一列,drop(labels,axis,inplace=True)方法用于删除其中一列。
Pandas内置了10多种数据源读取函数,可以方便地读取CSV和Excel文件。在读取CSV文件时,可以通过参数控制读取行为;在读取Excel文件时,需要注意编码问题。此外,还可以使用sqlalchemy建立数据库连接,通过pandas中的read_sql函数读取数据,并通过dataframe的to_sql方法保存数据。
数据清洗操作指南
除了工具之外,我们还需要了解一些数据清洗的基本操作和技巧。以下是一些常见的数据清洗操作:
缺失值是数据清洗中的一个重要问题。在处理缺失值时,我们可以首先确定缺失值的范围,然后根据缺失比例和字段重要性制定相应的解决策略。具体的处理方式包括删除缺失值、填充缺失值(如使用均值、中位数、众数等进行填充)或者通过其他变量的计算结果进行填充。
异常值是指相对于数据集其他点而言非常大或非常小的值。在处理异常值时,我们需要确定异常值的判断标准(如Q3+1.5xIQR或Q11.5xIQR),然后使用相应的函数(如lower_upper_range函数)进行处理。
数据不一致性是指在数据集中存在含义相同但表达方式不同的数据值。在处理数据不一致性时,我们需要对列名进行重命名,以确保数据分析的准确性。
以上就是数据清洗工具操作指南的主要内容。希望这些信息能够帮助你更好地进行数据清洗工作。