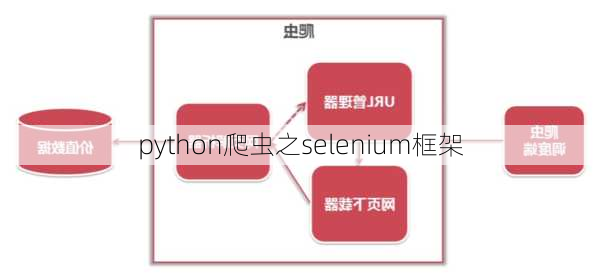
Selenium是一个用于测试Web应用程序的框架,它可以模拟用户在浏览器中的行为,因此也被广泛用于网络爬虫。在Python中,我们可以使用Selenium来编写爬虫程序。以下是关于Python爬虫之Selenium框架的一些信息:
1.支持多平台和多语言:Selenium支持Windows、Linux、Mac等多种操作系统平台,并且支持Python、Perl、PHP、C等多种编程语言。
2.支持多种浏览器:Selenium可以用于自动化测试和爬虫在多个浏览器上,包括Chrome、Firefox、Safari等。
3.操作直观:Selenium可以直接在浏览器中运行,就像真实用户操作一样。它可以控制浏览器进行点击、输入等操作,并获取相应的元素内容。
4.速度和灵活性:相比于传统的构造请求的爬虫,Selenium的速度可能会慢一些,因为它需要等待页面加载完毕才能继续执行。但是它提供了更高的灵活性,可以方便地处理一些反爬虫策略,如字体加密、图片替换数字等。
5.安装和使用:使用Selenium需要先安装Python的webdriver库,然后下载对应浏览器的驱动程序(如Chrome的chromedriver)。之后便可以通过Python代码
import
selenium.webdriver
来引入Selenium,创建浏览器实例并进行操作。
下面是一个简单的例子,使用Python的Selenium库打开百度搜索并查询某个关键词:
```python
from
selenium
import
webdriver
创建一个Chrome浏览器实例
driver
=
webdriver.Chrome()
访问百度搜索网站
driver.get('https://www.baidu.com')
找到搜索框并输入关键词
search_box
=
driver.find_element_by_name('wd')
search_box.send_keys('Python爬虫')
点击搜索按钮
search_button
=
driver.find_element_by_id('su')
search_button.click()
等待搜索结果页面加载完毕
driver.implicitly_wait(10)
获取搜索结果的标题
result_titles
=
driver.find_elements_by_class_name('title')
for
title
in
result_titles:
print(title.text)
关闭浏览器
driver.quit()
```
以上代码展示了如何使用Selenium打开百度搜索,输入关键词进行搜索,然后获取搜索结果的标题。注意其中的隐式等待(`implicitly_wait`)是为了让页面元素加载完成后再进行操作,避免因页面元素没有及时加载导致的操作失败。