
YARN容错性实现原理
YARN(Yet
Another
Resource
Negotiator)是Hadoop2.0版本新引入的资源管理系统,它通过一系列的容错机制来确保在面对硬件故障、网络故障或其他意外情况时,仍然能够保持系统的稳定性和可靠性。以下是YARN容错性实现的几个关键方面:
1.任务失败处理
在YARN中,任务失败是常见的问题,可能是由于代码运行异常或者其他未知原因导致。当一个任务失败时,它的JVM会在退出之前向其父applicationmaster发送错误报告,并将此次任务尝试标记为failed,然后释放容器以便资源可以为其他任务使用。此外,如果一个任务失败过4次,将不会再重试运行任务的最多尝试次数。在默认情况,如果任何任务失败次数大于4,整个作业都会失败。
2.ApplicationMaster失败处理
YARN中的应用程序在运行失败的时候会有几次尝试机会,就像mapreduce任务在遇到硬件或网络故障时要进行几次尝试一样。运行MapReduceapplicationmaster的最多尝试次数默认为2。超过后边不会再进行尝试,作业将失败。当applicationmaster失败时,资源管理器将检测到该失败并在一个新的容器(由节点管理器管理)中开始一个新的master实例。对于MapReduceapplicationmaster,它将使用作业历史来恢复失败的应用程序所运行任务的状态,使其不必重新运行。
3.NodeManager失败处理
如果节点管理器由于崩溃或运行非常缓慢而失败,就会停止向资源管理器发送心跳信息(或发送频率很低)。如果10分钟内没有收到一条心跳信息,资源管理器将会通知停止发送心跳信息的节点管理器,并且将其从自己的节点池中移除以调度启用容器。另外,对于那些曾经在失败的节点管理器上运行且成功完成的map任务,如果属于未完成的作业,那么applicationmaster会安排他们重新运行。
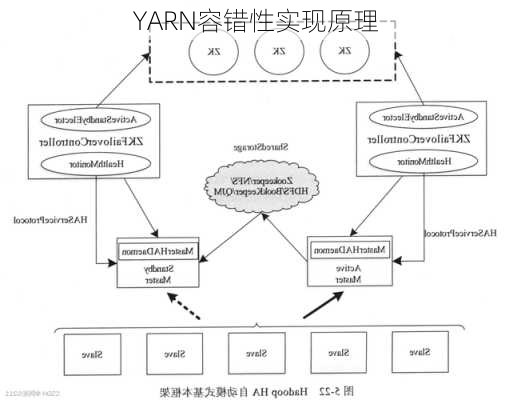
4.资源管理器失败处理
资源管理器失败时非常严重的问题,没有资源管理器,作业和任务容器将无法启动。在默认的配置中,资源管理器是个单点故障,这是由于在机器失败的情况下,所有运行的作业都失败且不能被恢复。为获得高可用性(HA),在双机热备配置下,运行一堆资源管理器是必要的。关于所有运行中的应用程序的信息存储在一个高可用的状态存储区中(由zookeeper或HDFS备份),这样备机可以恢复出失败的主资源管理器的关键状态。
通过上述容错机制的实施,YARN能够在面对各种故障情况时,迅速地恢复系统的正常运行,从而确保了大数据处理任务的稳定性和可靠性。







