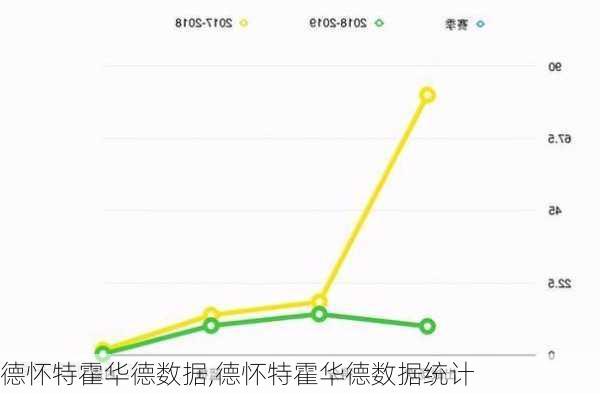
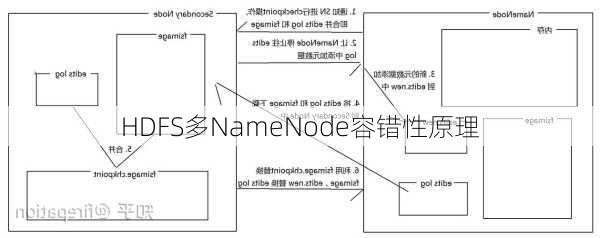
HDFS多NameNode容错性原理
Hadoop分布式文件系统(HDFS)通过其容错机制来确保数据的安全性和完整性。这种容错性体现在多个方面,包括数据块的***、心跳机制以及NameNode的角色和备份策略。
数据块的***
HDFS的一个关键特性是保存多个副本(默认为三个)的文件数据块。这种方式即使某个DataNode节点发生故障,也可以通过其他副本恢复数据。此外,HDFS还会定期将DataNode的状态信息发送给NameNode,以便NameNode能够监控DataNode的健康状况,并在必要时自动***新的副本。
心跳机制
DataNode通过心跳机制定期向NameNode发送状态信息。如果DataNode长时间没有发送心跳信息,NameNode会认为该节点已死,并尝试从其他DataNode上获取数据块的备份副本。
NameNode的角色和备份策略
NameNode是HDFS的管理核心,它负责管理文件系统的命名空间,包括文件和目录的目录树,以及每个文件对应的数据块列表。为了提高容错性,Hadoop引入了多NameNode的架构。在这种架构中,除了主NameNode外,还有一个或多个辅助NameNode(SecondaryNameNode)。辅助NameNode定期与主NameNode进行交互,例如,在Hadoop
1.x版本中,SecondaryNameNode会周期性地将主NameNode的日志文件进行合并,并清空日志文件,从而减少了主NameNode重启的时间。
当主NameNode发生故障时,辅助NameNode可以接管主NameNode的工作,从而确保了系统的连续运行。此外,为了进一步提高容错性,可以在不同的地理位置部署多个辅助NameNode,以防止单点故障。
总结
HDFS通过数据块的***、心跳机制以及多NameNode的架构实现了高度的容错性。这种容错性设计确保了在DataNode或NameNode节点发生故障的情况下,系统仍然能够正常提供服务,从而保证了大数据处理的稳定性和可靠性。