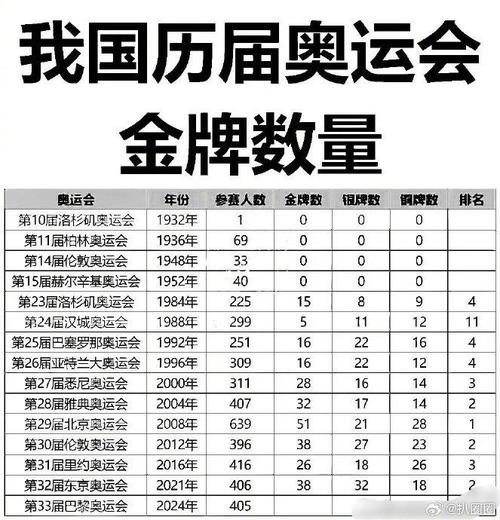
GFS的写入流程
GFS的写入流程主要包括以下几个步骤:
1.客户端向Master发起写入数据请求
首先,客户端需要知道要写入的数据应该在哪些ChunkServer上。Master会告诉客户端数据可以写入的副本位置信息,还要告诉客户端哪个是主副本PrimaryReplica,数据此时以主副本PrimaryReplica为准。
2.数据链式推送到所有副本
客户端拿到副本位置信息后,即:应该写入哪些ChunkServer里,客户端会把要写入的数据发送给所有副本。此时ChunkServer把接收到的数据放在一个LRU缓存中,并不真正地写数据。
3.主副本PrimaryReplica将LRU缓存中的数据写入实际的Chunk里
等所有次副本SecondaryReplica都接收完数据后,客户端就会给主副本PrimaryReplica发送一个写请求。因为客户端有成百上千个,会产生并发的写请求,因此主副本PrimaryReplica有可能收到很多客户端的写请求,主副本PrimaryReplica会将这些写请求排序,确保所有数据的写入是按照一个固定的顺序。主副本PrimaryReplica将LRU缓存中的数据写入实际的Chunk里。
4.次副本SecondaryReplica数据写完后,将回复主副本PrimaryReplica写入完毕
主副本PrimaryReplica把写请求发送给所有的次副本SecondaryReplica,次副本SecondaryReplica会和主副本PrimaryReplica以同样的数据写入顺序,将数据写入磁盘。次副本SecondaryReplica数据写完后,将回复主副本PrimaryReplica写入完毕。
5.主副本PrimaryReplica再去告诉客户端,这次数据写入成功了
如果所有副本都能正常接收和写入数据,那么主副本PrimaryReplica再去告诉客户端,这次数据写入成功了。如果有某个副本写入失败,也会告诉客户端,本次数据写入失败了。
在整个写入过程中,GFS会尽量最大化利用每个机器的网络带宽,避免网络瓶颈和高延迟连接,最小化推送延迟。这是因为GFS是基于廉价计算机硬件来设计的,我们知道单台机器性能瓶颈通常是硬盘,大数据系统是为海量数据而设计的,也必然要追求高性能,单台机器有硬盘的性能瓶颈,那就搭建成百上千台服务器,通过网络组成一个大数据集群,这个时候我们发现网络也会成为新的性能瓶颈。