HDFS与GFS的区别
1.设计理念和工作原理
HDFS(Hadoop分布式文件系统)和GFS(Google文件系统)都是分布式文件系统,但它们的设计理念和工作原理有所不同。
GFS的设计理念GFS是一个可扩展的分布式文件系统,它适用于大型分布式计算密集型应用程序。它的设计假设是系统构建于许多廉价的商用计算机上,发生故障是常态。因此,持续监控、错误检测、容错和自动恢复必须是系统的组成部分。GFS主要适用于大规模的流式读取,写操作主要是追加方式写,很少有随机写。GFS的核心思想是通过共同设计应用程序和文件系统的API来提高整个系统的灵活性。
HDFS的设计理念HDFS的设计目标是存储非常大的文件,采用流式的数据访问方式。它运行于商业硬件上,不需要特别贵的、reliable的(可靠的)机器。HDFS不适合低延时的数据访问和大量小文件的存储场景。
GFS和HDFS的工作原理也有所不同。GFS支持多客户端并发Append模型,允许文件被多次或者多个客户端同时打开以追加数据;而HDFS文件只允许一次打开并追加数据,客户端先把所有数据写入本地的临时文件中,等到数据量达到一个块的大小(通常为64MB),再一次性写入HDFS文件。
2.架构和组件
GFS的架构和组件GFS的架构由单个Master、多个chunkservers和多个访问clients组成一个GFS集群,其中每一个部分通常都是以用户级别的服务进程运行于商用Linux机器。Master维护文件系统所有的元数据(metadata),包括名字空间、访问控制信息、从文件到块的映射以及块的当前位置。ChunkServers基于Linux
filesystem在本地磁盘以Linuxfiles存储chunks;Clients通过指定chunkhandle和byterange读/写chunk数据。默认情况下每个chunk有三个副本,存储于不同的ChunkServer。
HDFS的架构和组件HDFS的架构也由Namesystem和Data
system两部分组成。Namesystem由NameNode和Secondary
NameNodes组成,负责管理和维护文件系统的命名空间以及客户端对文件的访问信息。Data
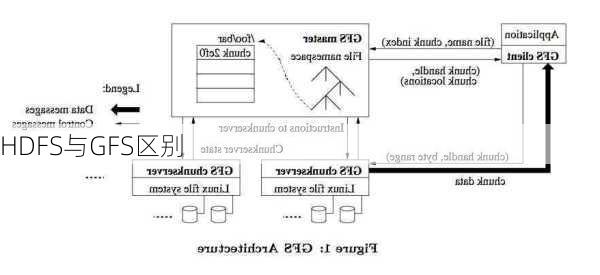
system由DataNodes组成,负责存储数据。HDFS在考虑写入模型时做了一个简化,就是同一时刻只允许一个写入者或追加者。在一个模型下同一个文件同一个时刻只允许一个客户端写入或追加。
3.写入模型和流程
GFS的写入模型和流程GFS使用租约机制来保障在跨多个副本的数据写入中保持顺序一致性。由主副本来确定一个针对该chunk的写入顺序,次副本则遵守这个顺序,这样就保障了全局顺序一致性。一旦所有的副本确认收到了数据,客户端将发送一个写请求控制命令到主副本。主副本转发写请求到所有次副本,次副本按主副本安排的顺序执行写入操作。
HDFS的写入模型和流程HDFS没有分离数据流和控制流。HDFS的数据流水线写入在网络上的传输顺序与最终写入文件的顺序一致。HDFS在写入数据时,是实时写入到物理块;而GFS是积攒到一定量,才持久化到磁盘。
4.性能和效率
GFS的性能和效率GFS的选择64MB作为块的大小,每一个块副本作为一个普通的Linux文件存储于ChunkServer并且仅在需要时进行扩展,使用惰性空间分配避免由于内部碎片造成空间浪费。这种设计减少了客户端与Master交互,同一块上的读写操作只需要Master发送一个初始化请求获取块的位置信息,维持一个持久的TCP连接减少网络开销,减少存储在Master上的元数据。
HDFS的性能和效率HDFS的设计更侧重于存储大文件,因此它的性能和效率在处理大文件时表现优秀。但是,在处理小文件时,由于文件系统的元数据(memory)限制,可能会出现性能瓶颈。
总的来说,GFS和HDFS都是优秀的分布式文件系统,它们各有优缺点,适用于不同的应用场景。