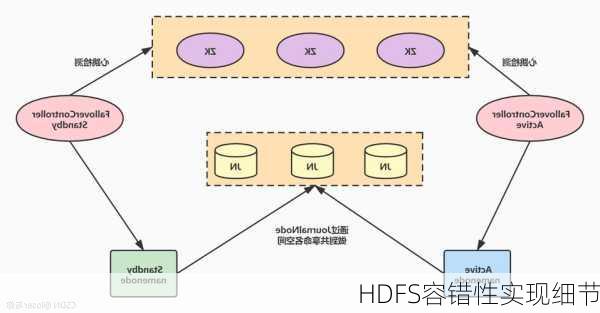
HDFS容错性实现细节
HDFS(Hadoop
Distributed
File
System)的容错性是通过多种机制实现的,主要包括以下几个方面:
1.文件系统容错
HDFS文件系统的容错主要通过以下几个机制实现:
NameNode高可用
NameNode是HDFS的元数据存储和管理节点,它保存着整个HDFS集群的元数据信息,包括文件名、所有者、所在组、权限、数据块和DataNode列表等。为了确保NameNode的高可用性,HDFS采用了NameNode高可用(HAA)机制。在HAA机制中,备NameNode会实时备份主NameNode上的元数据信息,一旦主NameNode发生故障不可用,备NameNode可以迅速接管主NameNode的工作。
SecondaryNameNode机制
SecondaryNameNode是HDFS中的一个后台进程,它的作用是对NameNode上的元数据进行定期的合并,以减少NameNode的内存消耗。在HDFS中,并不是所有的DataNode都会向NameNode发送心跳信息,而是通过SecondaryNameNode周期性地将部分DataNode的元数据信息下载到内存中进行合并。这样可以避免因大量DataNode的心跳信息导致NameNode内存耗尽的问题。
数据块副本机制
HDFS将数据文件切分成一个个小的数据块进行存储,并将这些数据块的副本保存多份,分别保存到不同的DataNode上。默认的副本存放策略是将第1个副本存放在HDFS客户端所在的节点上,第2个副本存放在与第1个副本不同的机架上,并且是随机选择的节点,第3个副本存放在与第2个副本相同的机架上,并且是不同的节点。这种副本存放策略可以确保在某些DataNode发生故障的情况下,仍然可以从其他DataNode上恢复数据。
心跳机制
DataNode会定期向NameNode发送心跳信息,将自身节点的状态告知NameNode。当NameNode连续10次没有收到DataNode的心跳报告时,会觉得DataNode可能死了,最终判断DataNode死亡需要一定的时间。此外,当某个DataNode上的空闲空间资源大于系统设置的临界值时,HDFS就会从其他的DataNode上将数据迁移过来;当某个DataNode上的资源出现超负荷运载时,HDFS也会根据一定的规则寻找有空闲资源的DataNode,将数据迁移过去。
2.Hadoop自身的容错
Hadoop自身的容错主要是指在升级Hadoop系统时,如果出现Hadoop版本不兼容的问题,可以通过回滚Hadoop版本的方式来实现自身的容错。
3.数据节点失效处理
当某个DataNode失效时,HDFS会通过心跳机制发现并标记失效的DataNode。然后,NameNode会重新计算数据块的最佳存放位置,并指示其他正常的DataNode接管失效DataNode的数据块。这样可以确保数据的持久性和完整性。
通过上述机制的协同工作,HDFS实现了高容错性的分布式数据存储方案,能够在DataNode发生故障的情况下,依然保证数据的可靠性和完整性。