Pandas处理缺失值的最佳实践
在数据分析和数据清洗的过程中,处理缺失值是一项重要的任务。Pandas库提供了多种方法来处理缺失值,包括删除、填充等策略。以下是根据搜索结果总结的Pandas处理缺失值的一些最佳实践。
在Pandas中,缺失值通常指的是`NaN`(Not
a
Number),这包括空字符串、空格、None等。理解缺失值的定义和类型是正确处理缺失值的前提。
Pandas提供了一些内置函数来检测缺失值,如`isnull()`和`notnull()`。这些函数可以返回一个布尔值的Series或DataFrame,表明哪些值是缺失值。此外,还可以使用`isna()`函数,它的结果与`isnull()`相同,与`notnull()`结果相反。
删除缺失值是一种常见的处理方式。`dropna()`函数可以根据每个标签的值是否是缺失数据来筛选轴标签,并根据允许丢失的数据量来确定阈值。默认情况下,`dropna()`会删除包含缺失值的行。可以通过设置`how='all'`参数来删除所有值均为缺失值的行或列。
填充缺失值是另一种常用的处理方式。`fillna()`函数可以用来填充缺失值,它可以接受一个常数或字典作为参数,用来替换缺失值。此外,还可以使用插值方法,如`ffill`(向前填充)和`bfill`(向后填充)来填充缺失值。
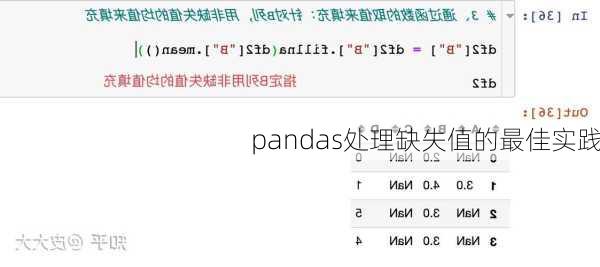
在处理缺失值时,需要考虑具体的业务场景。有时候,删除缺失值是合理的做法,特别是在数据集中缺失值比例较小的情况下。然而,如果缺失值比例较大,或者删除数据会对分析结果产生显著影响,则需要采用其他方法来填充或处理缺失值。
在使用Pandas进行数据分析之前,可能需要对数据进行预处理,例如检查并处理空字符串或空格等自定义缺失值。这可以通过使用`isin()`函数来判断,并将这些值替换成`np.nan`来进行。
虽然Pandas提供了丰富的缺失值处理功能,但在某些情况下,可能需要结合其他库的方法来处理缺失值。例如,sklearn库提供了`Imputer`类来处理缺失值。
以上就是根据搜索结果总结的Pandas处理缺失值的一些最佳实践。在实际应用中,需要根据具体情况选择合适的处理方法,并且始终关注数据质量和分析结果的准确性。