如何利用正则表达式进行数据清洗
在数据处理和分析的过程中,数据清洗是一个非常重要的环节。正则表达式(Regular
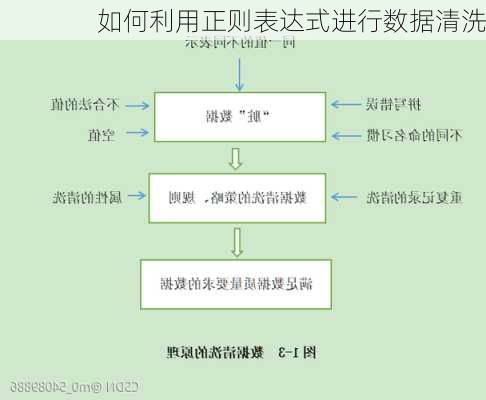
Expression)是一种强大的文本处理工具,可以用来进行各种复杂的文本匹配和替换操作,从而实现数据清洗的目的。以下是利用正则表达式进行数据清洗的一些常见方法和步骤:
正则表达式的`re.sub()`函数可以用来替换文本中符合某个模式的所有内容。在数据清洗中,我们可以使用这个函数来去除多余的字符、HTML标签、换行符等干扰信息。例如,可以使用`re.sub('外勤','',str(x))`来替换字符串`x`中所有的“外勤”。
正则表达式还可以用来从文本中提取有用的信息,如电子邮件地址、电话号码、日期等。通过编写相应的正则表达式,我们可以轻松地从大量的文本数据中提取出所需的结构化数据,以便后续的分析和挖掘。例如,可以从网页HTML标签中提取文本。
数据清洗通常包括以下步骤:
选择子集:对不需要的数据进行隐藏。
列名重命名:确保每个字段都有清晰的名称,便于理解和使用。
删除重复值:去除数据中的重复记录,避免分析时产生误导。
缺失值处理:可以选择删除、填充平均值或其他统计量来代替缺失值。
一致化处理:确保数据中的值都符合统一的标准或命名约定。
数据排序:根据需要对数据进行排序,以便更好地理解和分析。
异常值处理:识别并处理数据中的异常值,这些值可能是由于输入错误、测量误差或其他原因产生的。
在实际的数据清洗项目中,正则表达式可以用来处理各种类型的数据。例如,在新闻语料的清洗过程中,可以使用递归算法配合正则表达式来遍历读取大量的新闻文本,并进行实时的清洗和处理。
通过上述步骤和方法,我们可以有效地利用正则表达式进行数据清洗,从而为后续的数据分析和挖掘提供高质量的数据。需要注意的是,数据清洗是一个迭代的过程,可能需要多次检查和调整才能得到满意的结果。