根据您提供的信息,优化数据处理过程可以采取多种策略,具体取决于数据的性质、处理的需求和环境的限制。以下是一些常见的优化方法:
1.规则优化:
对数据处理的规则进行优化合并,减少进程的数目和存储空间的消耗。
精简数据处理流程,避免不必要的数据转换和操作。
2.分布式处理:
使用分布式计算框架如Hadoop或Spark,利用MapReduce等编程模型处理大规模数据集。
将数据分布在多个节点上并行处理,提高处理速度和效率。
3.索引优化:
在数据库中创建合适的索引,以加快查询速度。
根据查询的条件和频率,定期更新统计信息,优化索引策略。
4.查询优化:
优化SQL查询语句,避免全表扫描,使用高效的join算法。
利用缓存重用查询结果,减少数据库访问次数。
5.资源管理:
调整系统资源分配,如内存、CPU和磁盘I/O,以优先满足关键数据处理任务的需求。
使用资源调度工具,如YARN或Kubernetes,来管理集群资源。
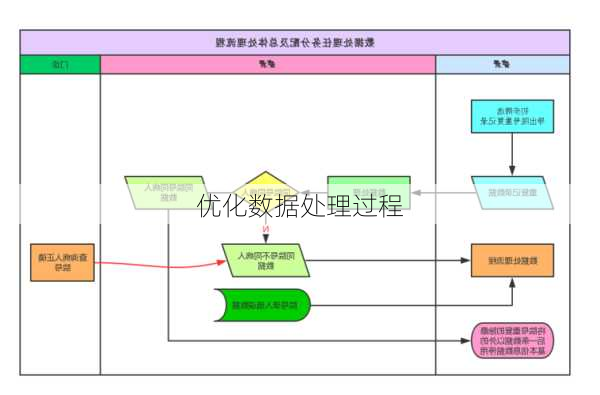
6.临时表和视图:
使用临时表暂存中间结果,减少重复计算。
视图可以简化复杂的查询表达式,方便后续的数据处理。
7.并行处理:
启用并行执行选项,让数据库能够并行处理大型查询。
调整并行度,平衡资源利用和处理速度。
8.分区表和分片:
对大表进行分区,以改善查询性能和数据管理。
数据分片允许数据跨多个物理位置分布,提高可扩展性和并发性。
9.批处理和实时处理:
根据数据处理场景,选择合适的处理模式(例如批处理、实时处理或流处理)。
批处理可以减少I/O次数,实时处理则能快速响应事件。
10.监控和调优:
实时监控数据处理系统的性能,识别瓶颈。
根据监控结果调整配置参数,持续优化处理过程。
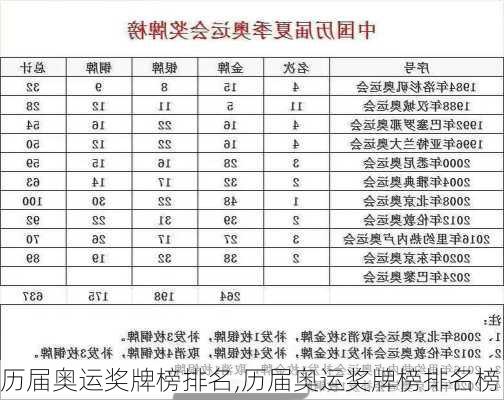
在您提供的例子[5]中,通过使用临时表、创建索引以及优化数据处理流程,将原本耗时的处理任务从4小时15分钟缩短到了25分钟,这充分展示了上述优化策略的有效性。在实际应用中,应根据具体情况综合考虑上述方法,并不断测试和调整以获得最佳性能。