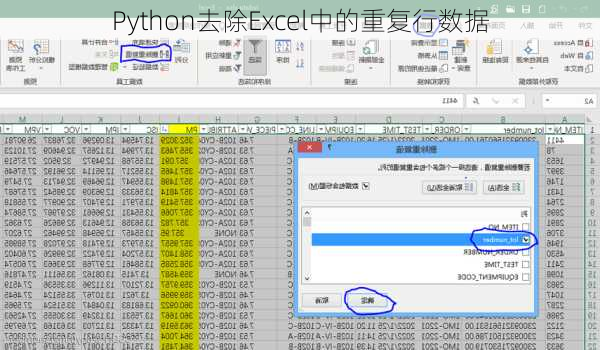
要使用Python去除Excel中的重复行数据,你可以采用pandas库,它提供了非常便捷的方法来处理数据。下面是一个简单的例子:
```python
import
pandas
as
pd
读取Excel文件中的数据
df
=
pd.read_excel('your_file_path.xlsx')
去除重复行,并且指定只保留第一个重复项(可选)
df
=
df.drop_duplicates()
或者如果你想指定特定的列作为唯一标识符,可以这样做:
df
=
df.drop_duplicates(subset=['column1',
'column2'])
保存去重后的数据到新的Excel文件
df.to_excel('output_file_path.xlsx')
```
这样,你就可以得到一个没有重复行的新Excel文件。如果你想要更详细的步骤或者不同的处理方式,请参考上面提供的博客文章[0]和[1]。